This is an old revision of the document!
Classification is an area of machine learning that determines discrete outputs. Similar to regression, classification models are based off of weights (or coefficients), w0 w1 w2 …, and the machine is trying to find a relationship between the independent variables, x1 x2 x3 …, and the dependent variable(s), typically just y. The difference between regression and classification is that classification problems have discrete outputs, for example the machine needs to predict if a tumor is malignant (yes/no). Another example would be that the machine needs to recognize whether or not a picture is a dog or a cat (dog/cat).
Classification methods discussed in this page:
- Logistic Regression
- K-Nearest Neighbors (K-NN)
- Support Vector Machine (SVM)
- Kernel SVM
- Naive Bayes
- Decision Tree Classification
- Random Forest Classification
Logistic Regression
Previously we used regression to find the best fit line for our data so that we can predict continuous outcomes. If we were to use linear regression on a dataset in Fig. 1 we would not get a model of the data that will allow us to accurately make predictions. Logistic regression uses a logistic function, commonly known as the sigmoid function, to classify data; The sigmoid function better fits binary data.
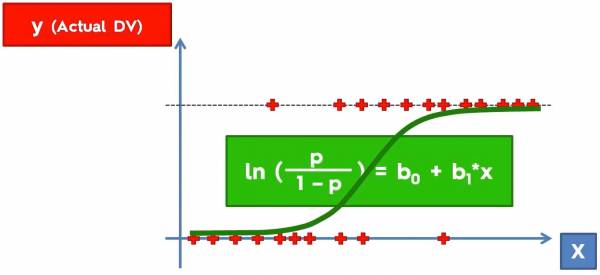 Fig. 1. Plot that shows some data with outputs (0 along the x axis and 1 along the dotted lines) and a sigmoid function in green.
Fig. 1. Plot that shows some data with outputs (0 along the x axis and 1 along the dotted lines) and a sigmoid function in green.
As an example fig. 1 is what actual data would look like; we have the independent variable, x, and the output y. Consider the example below:
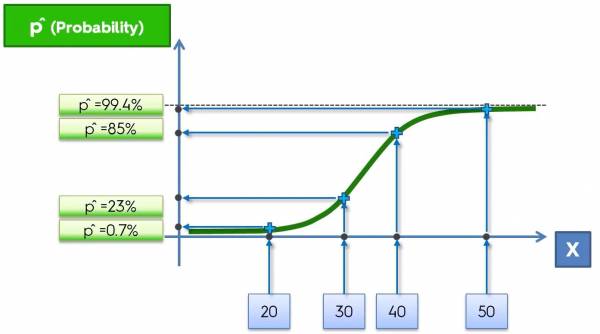 Fig. 2. Plot that imposes the data onto the sigmoid function.
Fig. 2. Plot that imposes the data onto the sigmoid function.
In this example, let's say that we want to classify whether or not a banana is genetically modified based on its length (in mm). So the length of the banana is the independent variable (x) and the classification (GMO or not GMO) is the dependent variable (y). Initially the data would look like Fig. 1, but now we are imposing the data onto the sigmoid function based on their values of x. Mapping the data onto the sigmoid function gives corresponding probabilities for the points and those probabilities are how the machine classifies the data. If the probability is less than 50% then the banana is not GMO and if it is greater than 50% then the banana is GMO.
Here is what the python implementation would look like (Does not include importing the dataset, splitting the dataset, and feature scaling):
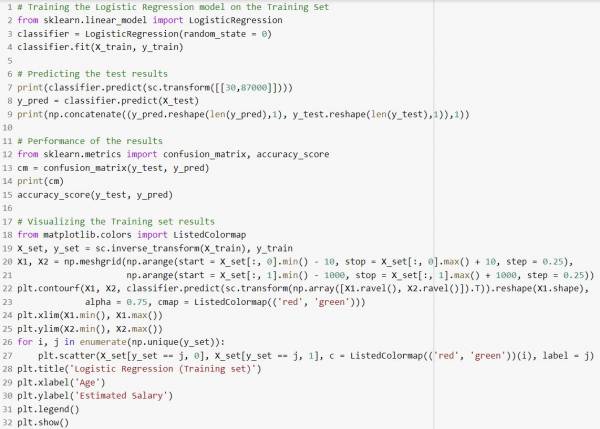
In this example the machine is trying to predict whether or not a person will predict a product based on that person's age and salary.
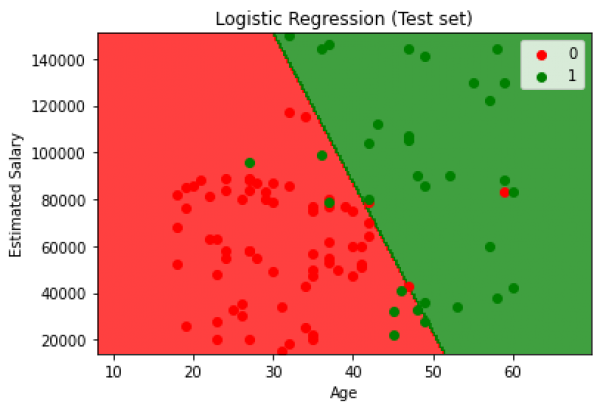
The accuracy of the given classification implementation in python is 89% and a visualization of the performance of the model is shown below: